Program Analysis - AP Computer Science A
Card 0 of 462
double square(double n){
return n*n;
}
What MUST be true immediately after the above code snippet has run?
double square(double n){
return n*n;
}
What MUST be true immediately after the above code snippet has run?
Squaring a real number will always produce a positive number. The result does not have to be stored in a new variable; it could be a value that is only needed for a one-off expression, thus, not worthy to be stored in memory. Lastly, since the input was passed by value and not by reference, its initial value will stay the same.
Squaring a real number will always produce a positive number. The result does not have to be stored in a new variable; it could be a value that is only needed for a one-off expression, thus, not worthy to be stored in memory. Lastly, since the input was passed by value and not by reference, its initial value will stay the same.
Compare your answer with the correct one above
Which of the following code excerpts would output "10"?
Which of the following code excerpts would output "10"?
Each bit of code has something similar to this:
num = (boolean statement) ? X : Y;
The bit at the end with the ? and : is called a ternary operator. A ternary operator is a way of condensing an if-else statement. A ternary operator works like this:
<boolean statement> ? <do this if true> : <do this if false>
The correct answer is
int num = 5;
num = (num > 0) ? 10: 11;
System.out.println(num);
Therefore, the ternary operator portion of code, when converted to an if-else, looks like this:
if (num > 0) {
num = 10;
else {
num = 11;
}
Because num is 5, which is greater than 0, it would go into the if, so num would then get 10. Then, num gets printed, which means 10 gets printed (the correct answer).
Each bit of code has something similar to this:
num = (boolean statement) ? X : Y;
The bit at the end with the ? and : is called a ternary operator. A ternary operator is a way of condensing an if-else statement. A ternary operator works like this:
<boolean statement> ? <do this if true> : <do this if false>
The correct answer is
int num = 5;
num = (num > 0) ? 10: 11;
System.out.println(num);
Therefore, the ternary operator portion of code, when converted to an if-else, looks like this:
if (num > 0) {
num = 10;
else {
num = 11;
}
Because num is 5, which is greater than 0, it would go into the if, so num would then get 10. Then, num gets printed, which means 10 gets printed (the correct answer).
Compare your answer with the correct one above
True or False.
The assertion in this code snippet is to prevent users from inputting bad data.
public class UserInput {
int userInput;
public static void main(String[] args) {
assertTrue(isInteger(args[0]));
userInput = args[0];
userInput = 25 - userInput;
}
}
True or False.
The assertion in this code snippet is to prevent users from inputting bad data.
public class UserInput {
int userInput;
public static void main(String[] args) {
assertTrue(isInteger(args[0]));
userInput = args[0];
userInput = 25 - userInput;
}
}
The assertion is used to validate user input. The user is able to input anything into the value at args\[0\]. Since this is the case, we must validate and make sure that the user is inputting what we want. To make this code snippet better, add error checking to do something if the user did not input an integer.
The assertion is used to validate user input. The user is able to input anything into the value at args\[0\]. Since this is the case, we must validate and make sure that the user is inputting what we want. To make this code snippet better, add error checking to do something if the user did not input an integer.
Compare your answer with the correct one above
Which of the following code excerpts would output "10"?
Which of the following code excerpts would output "10"?
Each bit of code has something similar to this:
num = (boolean statement) ? X : Y;
The bit at the end with the ? and : is called a ternary operator. A ternary operator is a way of condensing an if-else statement. A ternary operator works like this:
<boolean statement> ? <do this if true> : <do this if false>
The correct answer is
int num = 5;
num = (num > 0) ? 10: 11;
System.out.println(num);
Therefore, the ternary operator portion of code, when converted to an if-else, looks like this:
if (num > 0) {
num = 10;
else {
num = 11;
}
Because num is 5, which is greater than 0, it would go into the if, so num would then get 10. Then, num gets printed, which means 10 gets printed (the correct answer).
Each bit of code has something similar to this:
num = (boolean statement) ? X : Y;
The bit at the end with the ? and : is called a ternary operator. A ternary operator is a way of condensing an if-else statement. A ternary operator works like this:
<boolean statement> ? <do this if true> : <do this if false>
The correct answer is
int num = 5;
num = (num > 0) ? 10: 11;
System.out.println(num);
Therefore, the ternary operator portion of code, when converted to an if-else, looks like this:
if (num > 0) {
num = 10;
else {
num = 11;
}
Because num is 5, which is greater than 0, it would go into the if, so num would then get 10. Then, num gets printed, which means 10 gets printed (the correct answer).
Compare your answer with the correct one above
True or False.
The assertion in this code snippet is to prevent users from inputting bad data.
public class UserInput {
int userInput;
public static void main(String[] args) {
assertTrue(isInteger(args[0]));
userInput = args[0];
userInput = 25 - userInput;
}
}
True or False.
The assertion in this code snippet is to prevent users from inputting bad data.
public class UserInput {
int userInput;
public static void main(String[] args) {
assertTrue(isInteger(args[0]));
userInput = args[0];
userInput = 25 - userInput;
}
}
The assertion is used to validate user input. The user is able to input anything into the value at args\[0\]. Since this is the case, we must validate and make sure that the user is inputting what we want. To make this code snippet better, add error checking to do something if the user did not input an integer.
The assertion is used to validate user input. The user is able to input anything into the value at args\[0\]. Since this is the case, we must validate and make sure that the user is inputting what we want. To make this code snippet better, add error checking to do something if the user did not input an integer.
Compare your answer with the correct one above
double square(double n){
return n*n;
}
What MUST be true immediately after the above code snippet has run?
double square(double n){
return n*n;
}
What MUST be true immediately after the above code snippet has run?
Squaring a real number will always produce a positive number. The result does not have to be stored in a new variable; it could be a value that is only needed for a one-off expression, thus, not worthy to be stored in memory. Lastly, since the input was passed by value and not by reference, its initial value will stay the same.
Squaring a real number will always produce a positive number. The result does not have to be stored in a new variable; it could be a value that is only needed for a one-off expression, thus, not worthy to be stored in memory. Lastly, since the input was passed by value and not by reference, its initial value will stay the same.
Compare your answer with the correct one above
Consider the method
public String mystery(String s)
{
String s1 = s.substring(0,1);
String s2 = s.substring(1,2);
String s3 = s.substring(2, s.length() - 2);
String s4 = s.substring(s.length() - 2, s.length() - 1);
String s5 = s.substring(s.length() - 1);
if (s.length() <= 5)
return s5 + s4 + s3 + s2 + s1;
else
return s1 + s2 + mystery(s3) + s4 + s5;
}
What is the output of
System.out.println(mystery("ABNORMALITIES"));
Consider the method
public String mystery(String s)
{
String s1 = s.substring(0,1);
String s2 = s.substring(1,2);
String s3 = s.substring(2, s.length() - 2);
String s4 = s.substring(s.length() - 2, s.length() - 1);
String s5 = s.substring(s.length() - 1);
if (s.length() <= 5)
return s5 + s4 + s3 + s2 + s1;
else
return s1 + s2 + mystery(s3) + s4 + s5;
}
What is the output of
System.out.println(mystery("ABNORMALITIES"));
The .substring() method takes the character at the first number in the arguments, and goes through the String until it reaches the second number in the arguments, without copying the character at the second number.
In the first part of mystery(), the Strings s1, s2, s3, s4, and s5 are made and filled. If n = # of characters in s, s1 gets the first character in s, s2 gets the second character in s, s3 gets the third through n-2 characters, s4 gets the n-1 character, and s5 gets the last character.
String s1 = s.substring(0,1);
String s2 = s.substring(1,2);
String s3 = s.substring(2, s.length() - 2);
String s4 = s.substring(s.length() - 2, s.length() - 1);
String s5 = s.substring(s.length() - 1);
Let's look at the second portion of mystery().
if (s.length() <= 5)
return s5 + s4 + s3 + s2 + s1;
else
return s1 + s2 + mystery(s3) + s4 + s5;
The if statement checks the length of s, and if it's less than or equal to 5, it returns a String made from s5, followed by s4, etc. If s were equal to "abcde", then the if would evaluate to true, and would return "edcba". In recursion, this is known as the "base case".
The else statement is for strings that are greater than 5 characters in length. It returns s1, followed by s2, then the result of mystery(s3), then s4 and s5. The fact that it calls itself makes this recursion.
Let's step through the example. The argument for mystery(), s, is "ABNORMALITIES". After the first part, this is the result:
s1 = "A"
s2 = "B"
s3 = "NORMALITI"
s4 = "E"
s5 = "S"
Because s is longer than 5 characters, we take the else, so it returns the following:
A + B + mystery(NORMALITI) + E + S
Next, we repeat with the new argument. s = NORMALITI, so after the first part, the result is:
s1 = "N"
s2 = "O"
s3 = "RMALI"
s4 = "T"
s5 = "I"
Because s is longer than 5 characters again, we take the else, so it returns the following:
N + O + mystery(RMALI) + T + I
Which gets added to the previous return, making it this:
A + B + N + O + mystery(RMALI) + T + I + E + S
Once again, we repeat with the argument s = RMALI. After the first part, the result is:
s1 = "R"
s2 = "M"
s3 = "A"
s4 = "L"
s5 = "I"
Because s is less than or equal to 5 characters in length, we take the if this time. It returns the following:
I + L + A + M + R
We can replace all instances of mystery(RMALI) with the above, so the original return becomes this:
A + B + N + O + I + L + A + M + R + T + I + E + S
Which gets printed as ABNOILAMRTIES, the answer.
The .substring() method takes the character at the first number in the arguments, and goes through the String until it reaches the second number in the arguments, without copying the character at the second number.
In the first part of mystery(), the Strings s1, s2, s3, s4, and s5 are made and filled. If n = # of characters in s, s1 gets the first character in s, s2 gets the second character in s, s3 gets the third through n-2 characters, s4 gets the n-1 character, and s5 gets the last character.
String s1 = s.substring(0,1);
String s2 = s.substring(1,2);
String s3 = s.substring(2, s.length() - 2);
String s4 = s.substring(s.length() - 2, s.length() - 1);
String s5 = s.substring(s.length() - 1);
Let's look at the second portion of mystery().
if (s.length() <= 5)
return s5 + s4 + s3 + s2 + s1;
else
return s1 + s2 + mystery(s3) + s4 + s5;
The if statement checks the length of s, and if it's less than or equal to 5, it returns a String made from s5, followed by s4, etc. If s were equal to "abcde", then the if would evaluate to true, and would return "edcba". In recursion, this is known as the "base case".
The else statement is for strings that are greater than 5 characters in length. It returns s1, followed by s2, then the result of mystery(s3), then s4 and s5. The fact that it calls itself makes this recursion.
Let's step through the example. The argument for mystery(), s, is "ABNORMALITIES". After the first part, this is the result:
s1 = "A"
s2 = "B"
s3 = "NORMALITI"
s4 = "E"
s5 = "S"
Because s is longer than 5 characters, we take the else, so it returns the following:
A + B + mystery(NORMALITI) + E + S
Next, we repeat with the new argument. s = NORMALITI, so after the first part, the result is:
s1 = "N"
s2 = "O"
s3 = "RMALI"
s4 = "T"
s5 = "I"
Because s is longer than 5 characters again, we take the else, so it returns the following:
N + O + mystery(RMALI) + T + I
Which gets added to the previous return, making it this:
A + B + N + O + mystery(RMALI) + T + I + E + S
Once again, we repeat with the argument s = RMALI. After the first part, the result is:
s1 = "R"
s2 = "M"
s3 = "A"
s4 = "L"
s5 = "I"
Because s is less than or equal to 5 characters in length, we take the if this time. It returns the following:
I + L + A + M + R
We can replace all instances of mystery(RMALI) with the above, so the original return becomes this:
A + B + N + O + I + L + A + M + R + T + I + E + S
Which gets printed as ABNOILAMRTIES, the answer.
Compare your answer with the correct one above
Consider the Array
int[] arr = {1, 2, 3, 4, 5};
What are the values in arr after the following code is executed?
for (int i = 0; i < arr.length - 2; i++)
{
int temp = arr[i];
arr[i] = arr[i+1];
arr[i+1] = temp;
}
Consider the Array
int[] arr = {1, 2, 3, 4, 5};
What are the values in arr after the following code is executed?
for (int i = 0; i < arr.length - 2; i++)
{
int temp = arr[i];
arr[i] = arr[i+1];
arr[i+1] = temp;
}
We start with an array, arr, of size 5, containing {1, 2, 3, 4, 5}.
The loop in the code,
for (int i = 0; i < arr.length - 2; i++)
loops through the array up to the second to last cell, given that arr.length - 2 is the index of the second to last cell, and it starts at the first cell.
Let's look at the code inside the loop.
int temp = arr[i];
arr[i] = arr[i+1];
arr[i+1] = temp;
When i = 0,
arr[0] == 1
arr[1] == 2
temp = 1
arr[0] = 2
arr[1] = 1
arr[] == {2, 1, 3, 4, 5}
When i = 1
arr[1] == 1
arr[2] == 3
temp = 1
arr[1] = 3
arr[2] = 1
arr[] == {2, 3, 1, 4, 5}
When i = 2
arr[2] == 1
arr[3] == 4
temp = 1
arr[2] = 4
arr[3] = 1
arr[] == {2, 3, 4, 1, 5}
When i = 3
arr[3] == 1
arr[4] == 3
temp = 1
arr[3] = 3
arr[4] = 1
arr[] == {2, 3, 4, 5, 1}
As the loop progresses, it moves whatever value is in arr[0] all the way to the end of the array.
We start with an array, arr, of size 5, containing {1, 2, 3, 4, 5}.
The loop in the code,
for (int i = 0; i < arr.length - 2; i++)
loops through the array up to the second to last cell, given that arr.length - 2 is the index of the second to last cell, and it starts at the first cell.
Let's look at the code inside the loop.
int temp = arr[i];
arr[i] = arr[i+1];
arr[i+1] = temp;
When i = 0,
arr[0] == 1
arr[1] == 2
temp = 1
arr[0] = 2
arr[1] = 1
arr[] == {2, 1, 3, 4, 5}
When i = 1
arr[1] == 1
arr[2] == 3
temp = 1
arr[1] = 3
arr[2] = 1
arr[] == {2, 3, 1, 4, 5}
When i = 2
arr[2] == 1
arr[3] == 4
temp = 1
arr[2] = 4
arr[3] = 1
arr[] == {2, 3, 4, 1, 5}
When i = 3
arr[3] == 1
arr[4] == 3
temp = 1
arr[3] = 3
arr[4] = 1
arr[] == {2, 3, 4, 5, 1}
As the loop progresses, it moves whatever value is in arr[0] all the way to the end of the array.
Compare your answer with the correct one above
The function fun is defined as follows:
public int fun(int[] a)
{
a[a.length - 1] = a[0];
return a[0] + (a[0] % 2);
}
What is the value of a[0] after the following code segment is executed?
int[] a = {3, 6, 9, 12};
a[0] = fun(a);
The function fun is defined as follows:
public int fun(int[] a)
{
a[a.length - 1] = a[0];
return a[0] + (a[0] % 2);
}
What is the value of a[0] after the following code segment is executed?
int[] a = {3, 6, 9, 12};
a[0] = fun(a);
The first part of fun assigns the value of the last location of the array to the first location. Then, it returns the a[0] + (a[0] % 2). That last portion will be a "1" if a[0] is odd, and "0" if a[0] is even. Since a[0] == 12, which is even, the expression evaluates to 12 + 0, which is 12.
The first part of fun assigns the value of the last location of the array to the first location. Then, it returns the a[0] + (a[0] % 2). That last portion will be a "1" if a[0] is odd, and "0" if a[0] is even. Since a[0] == 12, which is even, the expression evaluates to 12 + 0, which is 12.
Compare your answer with the correct one above
What are the values of x, y, and z after the following code is executed?
int x = 4, y = 3, z;
for (int i = 0; i < 5; i++)
{
z = x + y;
y = x - y;
x = z;
}
What are the values of x, y, and z after the following code is executed?
int x = 4, y = 3, z;
for (int i = 0; i < 5; i++)
{
z = x + y;
y = x - y;
x = z;
}
The loop will run 5 times. The values of x, y, and z after each run will be as follows:
i == 0: x == 7, y == 1, z == 7 i == 1: x == 8, y == 6, z == 8 i == 2: x == 14, y == 2, z == 14 i == 3: x == 16, y == 12, z == 16i == 4: x == 28, y == 4, z == 28
At the end, i will equal 5, and the values will no longer change.
The loop will run 5 times. The values of x, y, and z after each run will be as follows:
i == 0: x == 7, y == 1, z == 7i == 1: x == 8, y == 6, z == 8i == 2: x == 14, y == 2, z == 14i == 3: x == 16, y == 12, z == 16i == 4: x == 28, y == 4, z == 28
At the end, i will equal 5, and the values will no longer change.
Compare your answer with the correct one above
BITWISE XOR OPERATION
Given the following binary values
a = 0100 1110
b = 0011 0101
perform an XOR operation (c = a^b). What is the result?
BITWISE XOR OPERATION
Given the following binary values
a = 0100 1110
b = 0011 0101
perform an XOR operation (c = a^b). What is the result?
Performing a bitwise excludive OR constitutes in taking both binary values and evaluating as follows: either one or the other (1) never both (0). This is the truth table for a bitwise XOR operation:
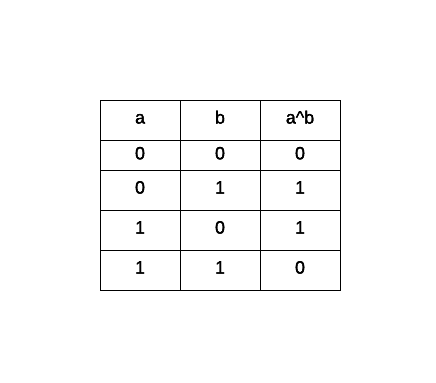
Taking both a and b and performing the operation bit by bit we get the following result:
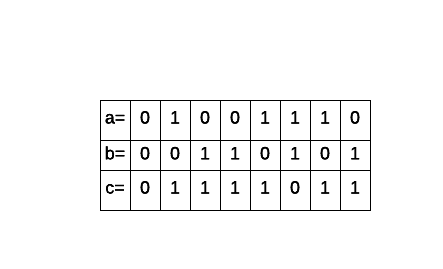
Performing a bitwise excludive OR constitutes in taking both binary values and evaluating as follows: either one or the other (1) never both (0). This is the truth table for a bitwise XOR operation:
Taking both a and b and performing the operation bit by bit we get the following result:
Compare your answer with the correct one above
True or False.
There is a runtime exception in this code snippet.
int wait_time = 0;
int wait_time = 5;
for (int i = 0; i < wait_time; i++) {
System.out.println(wait_time);
}
True or False.
There is a runtime exception in this code snippet.
int wait_time = 0;
int wait_time = 5;
for (int i = 0; i < wait_time; i++) {
System.out.println(wait_time);
}
Yes, there is a runtime exception in the code snippet. The int wait_time is defined twice which will give a runtime exception. This can be fixed by not declaring int before the second assignment of the variable wait_time.
Yes, there is a runtime exception in the code snippet. The int wait_time is defined twice which will give a runtime exception. This can be fixed by not declaring int before the second assignment of the variable wait_time.
Compare your answer with the correct one above
What is wrong with the following code?
- int main()
- {
- bool logic;
- double sum=0;
- for(j=0;j<3;j++)
- {
- sum=sum+j;
- }
- if (sum>10)
- {
- logic=1;
- }
- else
- {
- logic=0;
- }
- }
- }
What is wrong with the following code?
- int main()
- {
- bool logic;
- double sum=0;
- for(j=0;j<3;j++)
- {
- sum=sum+j;
- }
- if (sum>10)
- {
- logic=1;
- }
- else
- {
- logic=0;
- }
- }
- }
If you notice, in our for loop, the integer j is used as the iteration variable. However, no where in the code is that variable defined. To fix this issue this could have been done.
for (int j=0;j<3,j++)
Note the bold here is inserted. We need to define j here. We could have also defined j as a double.
If you notice, in our for loop, the integer j is used as the iteration variable. However, no where in the code is that variable defined. To fix this issue this could have been done.
for (int j=0;j<3,j++)
Note the bold here is inserted. We need to define j here. We could have also defined j as a double.
Compare your answer with the correct one above
FILE INPUT/OUTPUT
Consider the following C++ code:
1. #include
2. #include
3. using namespace std;
4. int main() {
5. ifstream outputFile;
6. inputFile.open("TestFile.txt");
7. outputFile << "I am writing to a file right now." << endl;
8. outputFile.close();
9. //outputFile << "I'm writting on the file again" << endl;
10. return 0;
11. }
What is wrong with the code?
FILE INPUT/OUTPUT
Consider the following C++ code:
1. #include
2. #include
3. using namespace std;
4. int main() {
5. ifstream outputFile;
6. inputFile.open("TestFile.txt");
7. outputFile << "I am writing to a file right now." << endl;
8. outputFile.close();
9. //outputFile << "I'm writting on the file again" << endl;
10. return 0;
11. }
What is wrong with the code?
Type ifstream objects are used to read from files, NOT to write to a file. To write to a file you can use ofstream. You can also you fstream to both read and write to and from a file.
Type ifstream objects are used to read from files, NOT to write to a file. To write to a file you can use ofstream. You can also you fstream to both read and write to and from a file.
Compare your answer with the correct one above
a. public void draw() {
b. int i = 0;
c. while(i < 15){
d. system.out.println(i);
e. i++
f. }
g. }
Which lines of code have errors?
a. public void draw() {
b. int i = 0;
c. while(i < 15){
d. system.out.println(i);
e. i++
f. }
g. }
Which lines of code have errors?
line d's error is that system.out.println (i); is not capitalized.
line e's error is that there is a missing semicolon.
line d's error is that system.out.println (i); is not capitalized.
line e's error is that there is a missing semicolon.
Compare your answer with the correct one above
Consider the following code:
int num = 1;
for(int i = 0; i < 10; i++) {
num *= i;
}
The code above is intended to provide the continuous product from num to 10. (That is, it provides the factorial value of 10!.) What is the error in the code?
Consider the following code:
int num = 1;
for(int i = 0; i < 10; i++) {
num *= i;
}
The code above is intended to provide the continuous product from num to 10. (That is, it provides the factorial value of 10!.) What is the error in the code?
This loop will indeed run 10 times. However, notice that it begins on 0 and ends on 10. Thus, it will begin by executing:
num *= 0
Which is the same as:
num = num * 0 = 0
Thus, you need to start on 1 for i. However, notice also that you need to go from 1 to 10 inclusive. Therefore, you need to change i < 10 to i <= 10.
This loop will indeed run 10 times. However, notice that it begins on 0 and ends on 10. Thus, it will begin by executing:
num *= 0
Which is the same as:
num = num * 0 = 0
Thus, you need to start on 1 for i. However, notice also that you need to go from 1 to 10 inclusive. Therefore, you need to change i < 10 to i <= 10.
Compare your answer with the correct one above
Consider the code below:
public class Clock {
private int seconds;
``
public Clock(int s) {
seconds = s;
}
``
public void setTime(int s) {
seconds = s;
}
``
public void setSeconds(int s) {
int hoursMinutes = seconds - seconds % 60;
seconds = hoursMinutes + s;
}
``
public void setMinutes(int min) {
int hours = seconds / 3600;
int currentSeconds = seconds % 60;
seconds = hours + min * 60 + currentSeconds;
}
}
Which of the following issues could be raised regarding the code?
Consider the code below:
public class Clock {
private int seconds;
``
public Clock(int s) {
seconds = s;
}
``
public void setTime(int s) {
seconds = s;
}
``
public void setSeconds(int s) {
int hoursMinutes = seconds - seconds % 60;
seconds = hoursMinutes + s;
}
``
public void setMinutes(int min) {
int hours = seconds / 3600;
int currentSeconds = seconds % 60;
seconds = hours + min * 60 + currentSeconds;
}
}
Which of the following issues could be raised regarding the code?
Recall that a "mutator" is a method that allows you to change the value of fields in a class. Now, for the setTime, setMinutes, and setSeconds methods, you do not check several cases of errors. For instance, you could give negative values to all of these methods without causing any errors to be noted. Likewise, you could assign a minute or second value that is greater than 60, which could cause errors as well. Finally, you could even make the clock have a value that is greater than "23:59:59", which does not make much sense at all!
Recall that a "mutator" is a method that allows you to change the value of fields in a class. Now, for the setTime, setMinutes, and setSeconds methods, you do not check several cases of errors. For instance, you could give negative values to all of these methods without causing any errors to be noted. Likewise, you could assign a minute or second value that is greater than 60, which could cause errors as well. Finally, you could even make the clock have a value that is greater than "23:59:59", which does not make much sense at all!
Compare your answer with the correct one above
for( int i = 0; i < n; ++i){
for( int j = 1; j < n; j *= 2){
someFunction();
}
}
For the code above, what is the run time in Big O notation?
for( int i = 0; i < n; ++i){
for( int j = 1; j < n; j *= 2){
someFunction();
}
}
For the code above, what is the run time in Big O notation?
At first glance we might be tempted to pick O(  ) because there are 2 for loops. But, upon closer inspection we can see that the first loop will yield a O( n ) running time but the second loop does not. The second loop has only an O( log(n) ) running time because "j" doubles each iteration and does not increase linearly. That will yield O( log(n) ) since O( log(n) ) is a much faster running time. So the final result is O( n log(n) ).
) because there are 2 for loops. But, upon closer inspection we can see that the first loop will yield a O( n ) running time but the second loop does not. The second loop has only an O( log(n) ) running time because "j" doubles each iteration and does not increase linearly. That will yield O( log(n) ) since O( log(n) ) is a much faster running time. So the final result is O( n log(n) ).
At first glance we might be tempted to pick O(
Compare your answer with the correct one above
Which is more efficient (i.e. Lower Big O)?
arr = \[1, 2, 3, 4, 5, 6, 7, 8\]
arr2 = \[\[1,2\],\[3,4\],\[5,6\], \[7,8\], \[9,10\], \[10, 11\]\]
for (int i = 0; i < arr.length; i++) {
for (int j = i; j < arr2.length; j++) {
arr\[i\]\[j\] = 0;
}
}
arr = \[1, 2, 3, 4, 5, 6, 7, 8\]
arr2 = \[\[1,2\],\[3,4\],\[5,6\], \[7,8\], \[9,10\], \[10, 11\]\]
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr2.length; j++) {
arr\[j\] = 0;
}
}
Which is more efficient (i.e. Lower Big O)?
arr = \[1, 2, 3, 4, 5, 6, 7, 8\]
arr2 = \[\[1,2\],\[3,4\],\[5,6\], \[7,8\], \[9,10\], \[10, 11\]\]
for (int i = 0; i < arr.length; i++) {
for (int j = i; j < arr2.length; j++) {
arr\[i\]\[j\] = 0;
}
}
arr = \[1, 2, 3, 4, 5, 6, 7, 8\]
arr2 = \[\[1,2\],\[3,4\],\[5,6\], \[7,8\], \[9,10\], \[10, 11\]\]
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr2.length; j++) {
arr\[j\] = 0;
}
}
Code sample #1 relies on i in the second loop where int j = i. Since the code relies on i in the second loop, the order goes from O(N) to O(N2)
Code sample #2 has two separate loops that do not rely on each other. The first for loop loops through the array arr and the second for loop loops through the array arr2. Since the two loops are exclusive, the order is O(N)
Code sample #1 relies on i in the second loop where int j = i. Since the code relies on i in the second loop, the order goes from O(N) to O(N2)
Code sample #2 has two separate loops that do not rely on each other. The first for loop loops through the array arr and the second for loop loops through the array arr2. Since the two loops are exclusive, the order is O(N)
Compare your answer with the correct one above
Which has faster compile time, O(N), O(N2), O(N3), or O(NlogN)?
Which has faster compile time, O(N), O(N2), O(N3), or O(NlogN)?
O(NlogN) is O(N) * O(logN) which is greater than O(N) alone.
O(N2) is O(N*N) which is greater than O(N).
O(N3) is O(N*N*N) which is greater than O(N).
O(N) is the smallest and therefore is the quickest to compile. Therefore, O(N) is the correct answer.
O(NlogN) is O(N) * O(logN) which is greater than O(N) alone.
O(N2) is O(N*N) which is greater than O(N).
O(N3) is O(N*N*N) which is greater than O(N).
O(N) is the smallest and therefore is the quickest to compile. Therefore, O(N) is the correct answer.
Compare your answer with the correct one above